ipad上下载手机版whatsapp


12月5日,当第一财经记者向一位云计算行业人士询问近期密集发生的App崩溃事件时,他转来刚刚发生的阿里云客户通知信息——又崩了。
官方页面信息显示,北京时间2023年12月5日10:15起,阿里云监控发现国内部分地域RDS(关系型数据库服务,Relational Database Service)备份恢复页面访问异常,经过阿里云工程师紧急处理,异常已于10:36恢复。
该人士对记者表示,互联网基础设施服务必然伴随不稳定性,“崩了”经常发生,只是看有没有被外界大范围注意到。但是像近期滴滴App如此大规模、广范围的负面影响,还是极少发生的。

第一财经记者梳理发现,今年以来,包括阿里、腾讯、百度、滴滴、抖音、B站等各大平台均发生过“崩了”事件。
12月3日晚,腾讯视频“崩了”登上微博热搜。腾讯视频方面回应称,出现了短暂技术问题,正在加紧修复,各项功能在逐步恢复中。
11月27日晚间,滴滴App系统发生故障,全国大面积崩溃,服务无法正常使用。11月29日,滴滴方面发表声明称,各项服务已经恢复,初步确定,这起事故的起因是底层系统软件发生故障,并非网传的“遭受攻击”。目前滴滴App的所有服务已经全部恢复。因这起事故给大家造成的困扰和问题,正在加快妥善解决。后续将深入开展技术风险隐患排查和升级工作,全面保障服务稳定性,尽最大努力避免类似事故再发生。
据记者不完全统计,B站在今年“崩了”两次,最近一次是在今年6月28日,当天下午不少用户反映“B站崩了”,该词条随后登上热搜。此次受影响的主要是番剧和影视页面,用户反映“追番一直提示获取视频内容失败”“显示页面加载失败”“看番看一半加载不出来”。该问题持续一小时左右,对于此次崩溃原因B站未有具体解释。
2023年3月5日20:20左右,在B站用户活跃的高峰期,许多网友发现B站手机和电脑端均无法访问视频详情页,当晚B站团队在出现故障20分钟后解决了问题。多位行业人士倾向于原因是“迭代更新出现代码故障”,这是2021年7月B站大规模服务器崩溃后的官方解释。
2021年7月13日或许是B站目前最大规模的服务器崩溃,当晚B站的手机和电脑端彻底无法使用,用户界面显示404或502,此次崩溃引发全网大讨论,一度登上热搜第一。14日凌晨2点20分,崩溃情况持续约3小时后,B站公告表示服务已陆续恢复正常,并道歉解释称是因为B站的部分服务器机房发生故障,造成无法访问。
2022年7月12日,B站技术团队官方账号“哔哩哔哩技术”发了一篇技术解析长文《2021.07.13 我们是这样崩的》,根据这篇文章的分析,服务器崩溃原因是当时新上线的代码函数存在问题,最终导致服务器CPU占满无法处理用户请求。
文章中提到,2021年7月13日22:52,SRE(负责站点可靠性的工程师)收到大量服务和域名的接入层不可用报警,客服侧开始收到大量用户反馈B站无法使用,甚至App首页也无法打开。基于报警内容,SRE第一时间怀疑机房、网络、四层LB、七层SLB等基础设施出现问题,紧急发起语音会议,拉各团队相关人员开始紧急处理。
经过原因排查后发现,B站出问题的模块是在线层 SLB(负载均衡服务器,用来处理多用户、多业务的情况)的CPU跑满了100%,无法处理用户请求,问题最终被定位到了最近新上线的 Lua(一种编程语言)函数上,这个函数因为代码错误运行出错陷入死循环导致过载。
如果不是滴滴的长时间崩溃造成大范围的负面影响与讨论度,非行业人士不会将某款软件的暂时“崩了”作为热点讨论。
万博智云CTO孙琦对第一财经表示,滴滴事件仅是一个个案,但该事件故障级别较大,确实影响到了一定规模普通群众的生活。实际上,很多用户看不到的软件故障正在每天发生,这在行业内是一个较为常见的问题。
一位软件工程师告诉记者,目前随着行业技术的逐渐成熟,各大厂一般都会自建数据中心,云服务也多采用多云策略,配有标准容灾机制,出现崩溃问题大多发生在自身算法、硬件,或自身技术团队层面。
以B站崩溃为例,其技术团队在解读文章中表示,运维团队做项目有个弊端,开发完成自测没问题后就开始灰度上线,没有专业的测试团队介入,“此组件太过核心,需要引入基础组件测试团队,对SLB输入参数做完整的异常测试。”
对于后续改进,B 站技术团队认为要“招专业做LB的人”,“我们选择基于Lua开发是因为Lua简单易上手,社区有类似成功案例。团队并没有资深做Nginx组件开发的同学,也没有做C/C++开发的同学。”
此外,文章里还提到,“B站一直没有NOC(网络操作中心)/技术支持团队,在出现紧急事故时,故障响应、故障通报、故障协同都是由负责故障处理的SRE(网站可靠性工程师)来承担。如果是普通事故还好,如果是重大事故,信息同步根本来不及,所以事故的应急响应机制必须优化。”
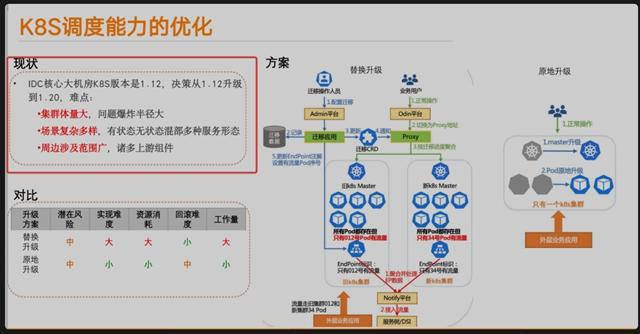
另以滴滴事件为例,多个独立信源向记者发来一份讨论截图,称一个规模非常大的K8s 集群进行在线热升级,因为某些原因,所有 Pod(容器)损坏,而 K8s 的元数据已经被新版本K8s 修改,无法回滚,因此恢复时间拉得很长。K8s(Kubernetes)是一个开源的容器编排平台,可以自动化地部署、扩展和管理容器化应用程序。
云猿生数据创始人兼CEO、前阿里云数据库总经理曹伟在其个人公众号发文解读称,该说法并非毫无依据。滴滴团队近两个月正将公司内部的 K8s 从1.12版本升级到1.20。前者于2018年9月发布,后者是2020年12月,对高速发展的K8s项目来说,两个版本间存在相当大差距。K8s 官方推荐的方法是沿着一个个版本升上去。但滴滴团队认为多次升级风险更高,采取了跨越八个版本直接升级策略,同时为了避免中断业务ipad上下载手机版whatsapp,在不重启容器的情况下原地升级,滴滴团队还修改了kubelet 的代码。曹伟认为该策略理论上可行,但中间可能遭遇到意外因素,如运维误操作,才导致了最终的大规模故障。
曹伟的建议是,当一个集群规模很大时,很容易在意想不到的地方发生类似的问题,那么在设计系统时,应把集群的规模控制在一个合理的范围,但扩大集群数量。
例如,可以把两个一万节点的集群拆成十个两千节点的集群,管理成本没有增加,而运行风险和(故障的)爆炸半径得到极大的降低。
11月12日,阿里云出现了一次影响所有区域的全局大故障。以这次阿里云的史诗级故障为例,曹伟称,对象存储的关键路径里依赖看RAM(内存)的鉴权逻辑,因此RAM出现故障时,也造成了对象存储的不可用。因此,数据面的可用性如果和控制面解耦,那么控制面挂掉对数据面的影响很轻微。否则,要么要不断去提高控制面的可用性,要么就要接受故障的级联发生。因此总结来说,曹伟建议各平台技术团队尽量做到控制规模、避免单点、拥抱重启、保证数据面的可用性和控制面解耦。
孙琦对记者表示,如今各大互联网平台基础架构层已经很成熟,极少出现因技术革新导致影响整个架构的事故,但在现有技术支撑、业务并发量不会暴涨的情况下,在团队稳定的前提下,类似问题理应不会频繁出现。
