自定义ip代理软件安卓


1.APP的爬取比Web爬取更加容易,反爬虫没有那么强,且大部分数据是以JSON形式传输的,解析简单。
2.在APP中想要查看请求与响应(类似浏览器的开发者工具监听到的各个网络请求和响应),就需要借助抓包软件。
3.在抓取之前,需要设置代理将手机处于抓包软件的监听下,就可以用同一网络进行监听,获得所有的网络和请求。
4.如果是有规则的,就只需要分析即可;如果没有规律,就可以用另一个工具mitmdump对接Python脚本直接处理Response。
5.抓取肯定不能由人手动完成,还需要做到自动化,还要对App进行自动化控制,可以用库Appium。
Charles是一个网络抓包工具,比Fiddler功能更强大,可以进行分析移动App的数据包,获取所有的网络请求和网络内容
charles是收费软件,但可以免费试用30天。试用期过了,还可以试用,不过每次试用不能超过30分钟,启动有10秒的延迟,但大部分还可以使用。

现在很多网页都在向HTTPS(超文本传输协议的加密版,即HTTP加入SSL层),经过SSL加密更加安全,真实,大部分都由CA机构颁发安全签章(12306不是CA机构颁发,但不被信任)。现在应用HTTPS协议的App通信数据都会是加密的,常规的截包方法是无法识别请求内部的数据的。
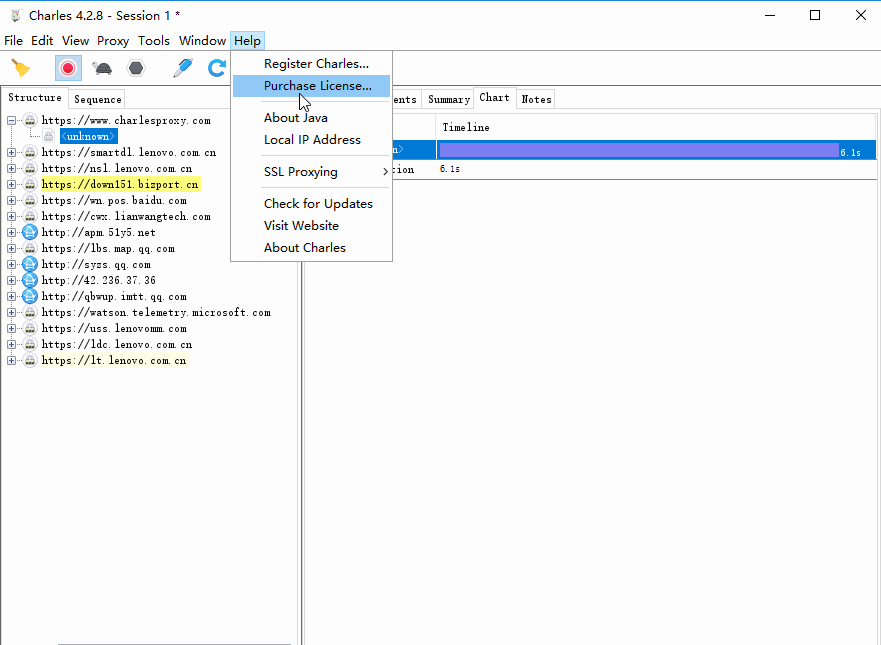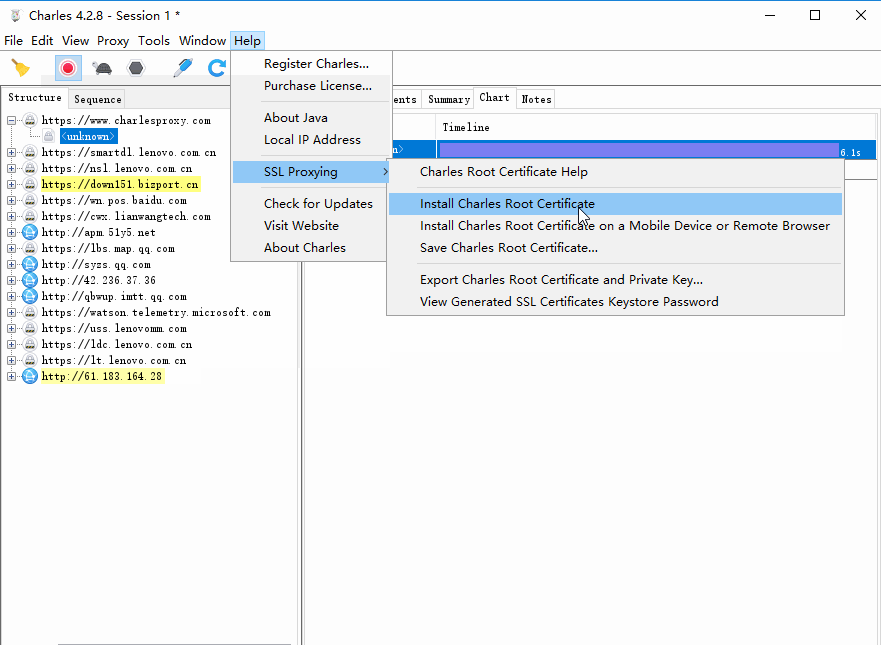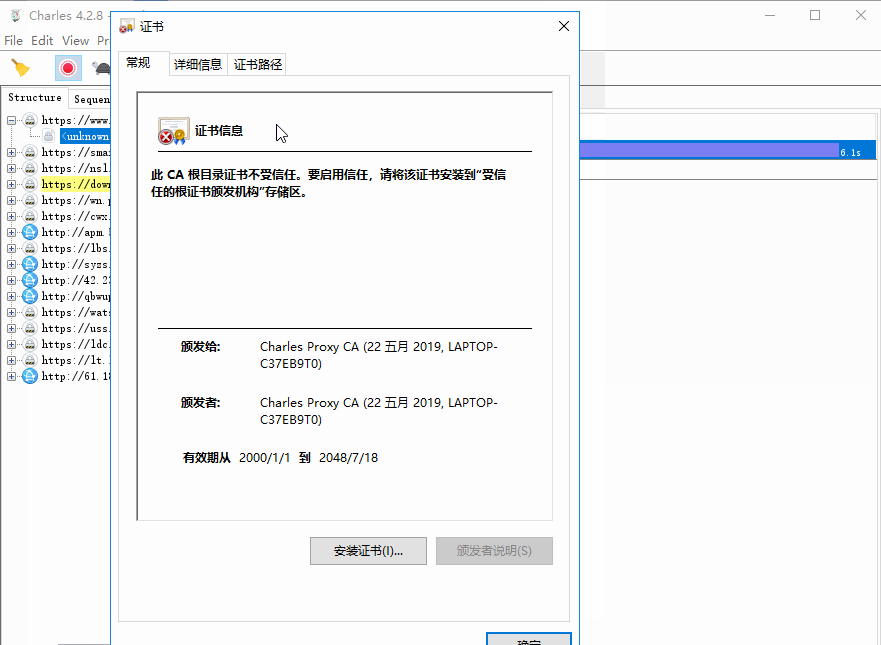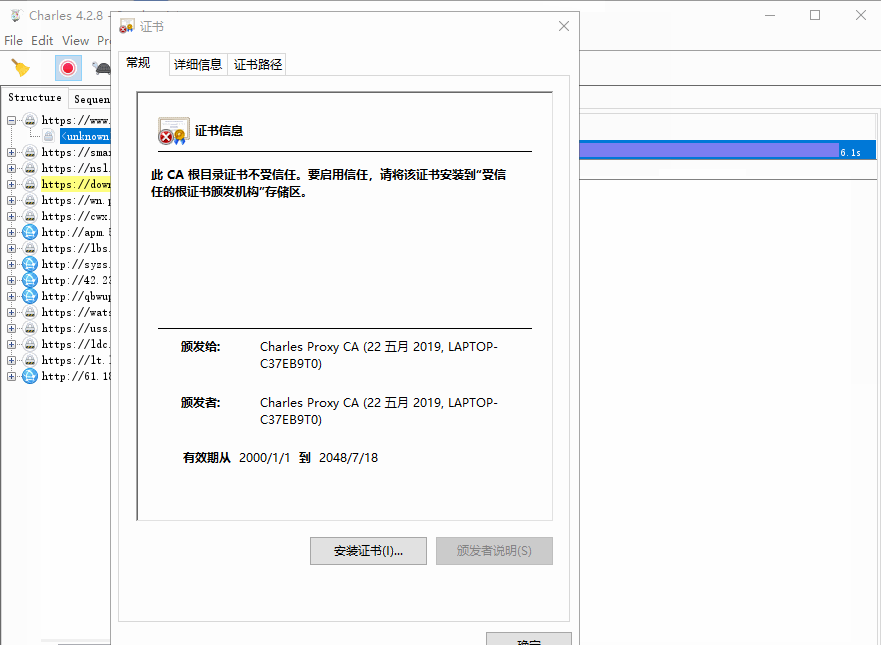
点击安装证书,就会打开证书安装向导,然后点击下一步,此时需要选择证书的存储区域,选择第二个选项”将所有证书放入下列存储”:
为10.61.131.172,默认代理端口号为8888。之后代理服务器为电脑的IP地址。端口为8888。设置如下:
点击Proxy-SSLProxying Settings,在弹出的窗口中点击Add按钮,添加需要监听的地址和端口号。需要监听所有的HTTPS请求,可以直接将地址和端口设置为,即添加:*设置,就可以抓取所有的HTTPS请求包;如果不配置,抓取的HTTPS请求包状态可能是unknown。


Charles运行时会在PC端的8888开启一个代理服务,实际上是一个HTTP/HTTPS的代理。
可以是用手机通过相同的无线网络连接(这里用的是校园网),设置手机代理为Charles的代理地址,这样手机访问互联网的数据就会经过Charles抓包工具,Charles转发这些数据到真实的服务器,再转发到手机中。这样抓包工具(Charles)就起到了中间人的作用,还有权对请求和响应进行修改。
我们可以看到我们已经请求了很多数据了,点击左上角的扫帚按钮即可清空捕获到的所有请求,然后点击第二个监听按钮,表明Charles正在监听App的网络数据流。如下:
这是有规则的,无规则的如果没有规律的url,就可以用另一个工具mitmdump对接Python脚本直接处理Response。
mitmproxy是一个支持HTTP和HTTPS的抓包程序,有类似Fiddler和Charles的功能,但它是一个控制台的形式操作。
mirmproxy还有两个关联组件。一个是mitmdump,是命令行接口自定义ip代理软件安卓,可以对接Python脚本,用Python处理数据;另一个是mitmweb,是一个web程序,可以清楚地查看mitmproxy捕获的请求。


直接下载即可,安装之后需要c++的库之类的东西都安装了,然后再在命令行进行安装 mitmproxy即可:


在“安装 Visual Studio”屏幕中找到所需的工作负载,选择使用的桌面开发C++工作负荷:


对于mitmproxy来说,如果想要截获HTTPS请求,也需要设置证书。它在安装后会提供一套CA证书,只要客户端信任了mitmproxy的证书,就可以通过mitmproxy获取HTTPS请求的具体内容,否则无法解析HTTPS请求。
手动更改为.crt 格式,最后随便放进某个文件夹即可,用手机(我用的360手机)设置里的安全,找到从存储设备安装找到该crt文件进行配置:


在mitmproxy中,会在PC端的8080端口运行,然后开启一个代理服务,就是一个HTTP/HTTPS代理,类似ip代理。
手机和PC在同一局域网内,设置代理为mitmproxy的代理地址,抓包工具mitmproxy就相当于中间人的作用,数据就会流经抓包工具。这个过程还可以对接mitmdump,抓取到的请求和响应都可以直接用Python来处理,然后分析,存到本地,或存到数据库。
在cmd中输入mitmproxy,会在8080端口运行一个代理服务,由于该命令不支持Windows系统,因此在Windows系统中用mitmdump命令:
在mitmproxy中它的强大体现到mitmdump工具,可以对接Python对数据请求进行处理。
它是mitmproxy的命令行接口,可以对接python程序对请求进行处理,不需要手动截取和分析HTTP请求和响应,进行数据存储和解析都可以通过Python来完成。


输入mitmdump -w outfile(outfile名称和扩展名可以自定义,文件放到当前cmd打开目录下,也可以用绝对相对路径,但比较麻烦):
Mitmdump -s script.py(脚本名字可以自定义),需要放在cmd当前目录下,也可以用绝对相对路径,但比较麻烦。

就是定义了一个request()方法,参数为url,其实是一个HTTPFlow对象,通过request属性即可获取到当前请求对象。然后打印出请求头,将User-Agent(用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言浏览器插件等)修改为MitmProxy。


mitmdump提供了专门的日志输出功能,就是设定输出到控制台的颜色,可以分别为不同级别配置不同的颜色,更加直观:


还可以把这些请求的信息进行修改后,再发送到服务器中,这样,服务器返回的可能不是app想请求的网页,这就是为什么一些app打开后却访问到了其他网址的原因。
对于json格式文件,mitmdump也提供了对应的处理接口,就是response()方法。
我们可以打印各个http/https请求的响应内容,不过text才是我们想要的json格式文件,也可以用content,不过返回的是二进制文件。
代码在pa_qu_json.py文件中,需要先创建一个json爬取数据文件夹,爬取后的结果如下:


接下来用Python处理即可,这里只是简单爬取。在实际应用中,不是人工的,是用代码自动化进行分析各个请求和响应进行爬取。这里有个跨平台的移动端自动化测试工具,可以很方便地进行自动化爬取,在下一个爬虫博客中会详细讲到,希望大家把宝贵意见提出来一起学习进步。
在开始编写爬虫之前,必须先配备相应的工具和库。首先,确保Python环境已经安装好,然后使用pip安装请求库requests和分析库BeautifulSoup4。使用这两个数据库可以帮助我们从网页中提取所需的影评数据。# 安装所需库pip install requestspip install beautifulsoup4有了这些准备工作,我们需要了解目标网站的结构及其请求规则。打开浏览器,进
模拟登录要想实现对知乎的爬取,首先我们要实现模拟登录,因为不登录的话好多信息我们都无法访问。下面是登录函数,这里我直接使用了知乎用户fireling的登录函数,具体如下。其中你要在函数中的data里填上你的登录账号和,然后在爬虫之前先执行这个函数,不出意外的话你就登录成功了,这时你就可以继续抓取想要 的数据。注意,在首次使用该函数时,程序会要求你手动输入captcha码,输入之后当前文件夹会多
## 爬取手机App的简介与应用实例爬取手机App是指通过编程语言Python来从手机应用商店或其他渠道获取手机应用程序的相关信息,例如应用名称、版本号、开发者、下载量、用户评论等。这种技术在市场调研、竞争分析、用户行为分析等领域有着重要的应用。### 爬取手机App的方法和工具爬取手机App的方法有很多种,常见的方法包括使用API接口、模拟用户操作、解析网页等。而使用Python进行
# Python爬取手机APP内容随着智能手机的普及,手机APP已成为我们日常生活中不可或缺的一部分。有时我们可能会想要获取某个APP中的内容,比如应用的介绍、评论或者其他的一些有用信息。幸运的是,我们可以使用Python来实现这一目标。本文将介绍如何使用Python来爬取手机APP的内容,并提供代码示例。## 1. 确定目标APP首先,我们需要确定我们想要爬取的目标APP。无论是iO
# Python爬取手机APP数据的流程本文将介绍如何使用Python来实现爬取手机APP数据的过程,并提供详细的步骤和示例代码。希望对刚入行的小白开发者有所帮助。## 整体流程以下是爬取手机APP数据的整体流程概览: 步骤 操作 --- --- 1 寻找目标APP 2 分析APP的数据请求 3 发送数据请求并获取数据
今天向大家介绍app爬取。文章目录一:爬取主要流程简述二:抓包工具Charles1.Charles的使用2.安装(1)安装链接(2)须知(3)安装后3.证书配置(1)证书配置说明(2)windows系统安装证书配置(3)Android手机安装证书配置4.开启SSL监听5.原理6.抓包三:抓包工具mitmproxy(免费的)1.简介2.关联组件3.安装和证书配置(1)用
我们在爬取手机APP上面的数据的时候,都会借助Fidder来爬取。今天就教大家如何爬取手机APP上面的数据。Python学习资料或者需要代码、视频加Python学习群:516107834环境配置1、Fidder的安装和配置下载Fidder软件地址
# Python爬取手机APP的数据## 1. 简介在移动互联网时代,每个人都在使用各种各样的手机APP。作为开发者,我们可能需要获取某些APP的数据来进行分析或者业务拓展。本文将介绍如何使用Python来爬取手机APP的数据。在学习爬取手机APP的数据之前,我们需要先了解一些基础知识。首先,了解HTTP协议和请求响应的基本原理。其次,了解APP的接口和数据传输方式。最后,了解Pyth
# Python如何爬取手机APP数据## 问题描述我们现在有一个具体的问题:我们想要获取某个旅行App上的景点信息和用户评论数据,以便进行分析和统计。但是该App没有提供公开的API,我们无法直接获取数据。那么,我们应该如何使用Python来爬取这个App的数据呢?## 解决方案### 1. 分析App的网络请求首先,我们需要分析该App的网络请求,找出获取景点信息和用户评论
如何使用Python爬取抖音手机APP作为一名经验丰富的开发者,我将教你如何使用Python来爬取抖音手机APP的内容。在开始之前,我们需要确保你已经具备一些基础的Python编程知识,并安装了相应的Python库。整个过程可以分为以下几个步骤:1. 确定目标:首先,我们需要明确我们想要爬取抖音APP中的哪些内容。比如,我们可以爬取用户的基本信息、视频的评论、点赞数等等。确定好我们的目
工具:windows,pycharm,appium 第一步:环境搭建: 运行之前将环境调试好,需要安装Android,java,nodejs,appium 安装方法自行百度。 安装好之后,打开cmd,输入appium,出现如下界面,说明你的环境搭建好了。第二步:配置手机: 打开手机的usb开发者模式,打开方式自行百度。 小米的要再打开一个usb调试(安全设置),这个原来没打开,死活连不上。第三步:
1. 爬取前的分析mitmdump是mitmproxy的命令行接口,比Fiddler、Charles等工具方便的地方是它可以对接Python脚本。有了它我们可以不用手动截获和分析HTTP请求和响应,只需写好请求和响应的处理逻辑即可。它还可以实现数据的解析、存储等工作,这些过程都可以通过Python实现。1.1 启动mitmdump 保存到文件使用命令mitmdump -w crawl.txt其中
我们之前一直都在爬取网页数据,但有些企业并没有提供web网页服务,而是提供了app服务,还有些web网页数据的各种反爬虫措施太牛逼,这时候如果从app端爬取兴许更容易得多,本篇就来介绍app数据如何爬取作为案例,选用简单的王者荣耀盒子 的英雄胜率排行榜方法:1. 利用抓包工具(例如 Fiddler)得到包含所需数据的 url 以及数据的格式2. 用代码模拟数据请求操作步骤:一、环境搭建
现在手机应用越来越多,大家也都习惯了用手机上网,爬取手机上的数据就成为爬虫们的必要工作。爬取手机资料的基本原理是用抓包工具抓取手机访问网页或者APP过程中的数据,然后进行解析。因为手机上的数据大部分是格式化的,主要是json格式,所以相对来说解析比较容易,难度主要就在于如何抓包,并从一大堆杂乱无章的数据包中找到需要的数据。抓包有很多工具,比较常用的是fiddler。抓包工具 FiddlerFidd
公司最近要做一款手机,手机需要制作一个应用市场。那么问题来了,自己制作应用市场,数据从哪来呢?作为一个创业型公司。搜集数据变成为了难题。于是突然想到能不能通过程序去抓取别人应用市场的数据……那么我们一步一步的来看,如何抓取华为应用市场的APK信息。首先打开华为官网看到如下页面。然后我们在谷歌浏览器中按F12查看一下下载是否是明文链接随便选择一个 ,右键查看下载的属性。在这里我们可以看见a标签的on
需求分析:我们要爬取华为商城手机类别的所有手机参数。但是不要配件的。1、按F12,随便搜索一个关键字,找到对应的接口。找到的接口是:Request URL:
第一步:先分析这个url,”?“后面的都是它的关键字,requests中get函数的关键字的参数是params,post函数的关键字参数是data,关键字用字典的形式传进去,这样我们就可以自己改关键字去搜索别的东西或者是搜索别的页面,我对手机比较感兴趣所以就爬取了关于手机的页面。第二步:直接先给出源代码,然后细节再慢慢的说。# encoding:utf8import requestsimpor
之前写了一个自动签到的脚本,我姐本来让我给她写一个手机app自动签到的脚本的,后来发现自己不会爬手机app,现在抽时间找了教程,看完教程后来爬一下手机app试一试。在爬手机app时先要安装的的软件是Fiddler :下载地址: 密码: r8kg安装好Fiddler后打开.exe文件,开始配置,首先点击
实现工具scrapyBeautifulSouprequests原理分析打开京东首页,搜索裤子将会打开裤子页面如:这里,这个页面的数据就是我们要将要获取的。我们可以看到这个页面当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到页面又多加载了30条数据,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信息都在1这个标签中,如下图:接着我们打开网
MySQL的InnoDB的细粒度行锁,是它最吸引人的特性之一。但是,如《InnoDB,5项最佳实践》所述,如果查询没有命中索引,也将退化为表锁。InnoDB的细粒度锁,是实现在索引记录上的。一,InnoDB的索引InnoDB的索引有两类索引,聚集索引(Clustered Index)与普通索引(Secondary Index)。InnoDB的每一个表
