苹果手机在国内怎么使用whatsapp


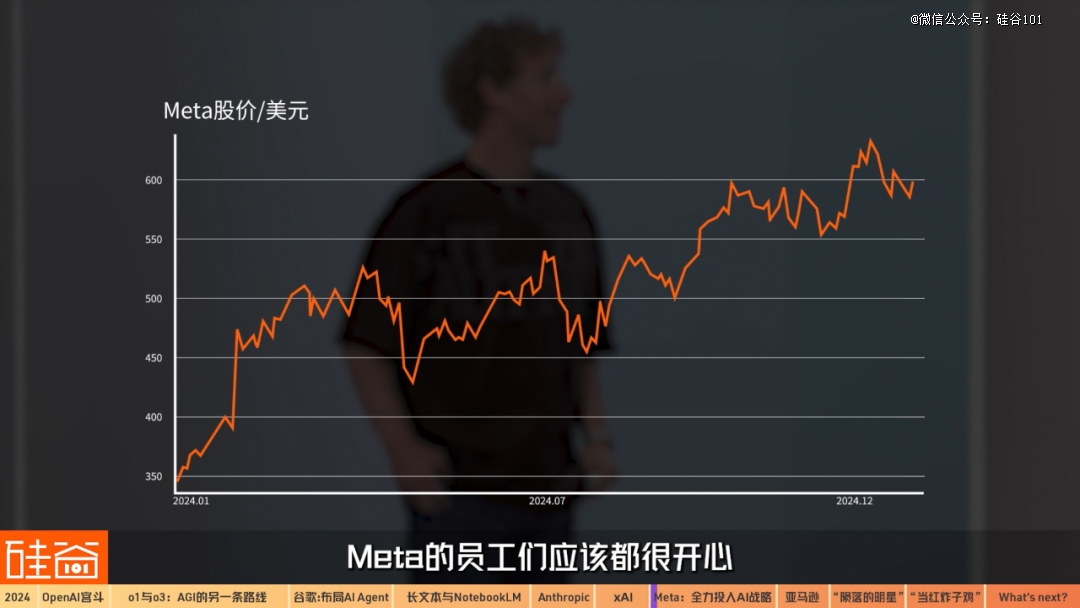
巨头们不但拼模型能力,还拼爆款产品,同时继续投入数百亿美元拼算力建数据中心;而几家一年前还是明星项目的初创企业却因为资金烧光,直接被巨头吞并。
在学术界,技术*们对AI的未来依然争论不休、骂战不断:GPT5依然没有踪影,Scaling law甚至被认为已经遇阻“撞墙”。
然而2024年底,谷歌Gemini 2.0的发布,以及OpenAI一连12天发布更新,却让大家对2025年AI的进展又有了一些新的期待...
这期内容我们将回顾下生成式AI在硅谷的2024年有哪些drama,又有哪些实在的技术进展和路线年的AI会如何发展。
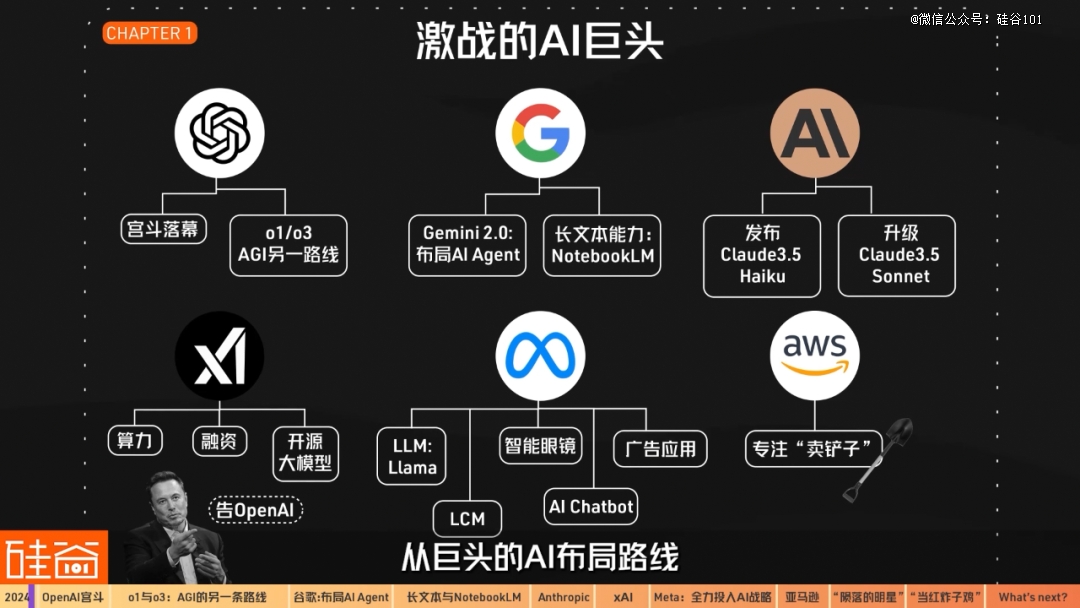
我们将结合与技术大佬的采访聊天,从巨头的AI布局路线、产品落地、陨落的明星公司和冉冉升起的新星们,以及业内对2025年AI展望这几条主线来展开,看看过去一年都发生了些什么。
OpenAI在2024年的drama并不少:2023年底的董事会风波之后,2024年OpenAI的高层依然极度不稳定,人才流动性很大。
联合创始人、首席科学家Ilya Sutskever在五月离职。之后他宣布创办自己的初创公司Safe Superintelligence,快速融资了10亿美元。

和Ilya一起离职的还有超级对齐团队的关键技术人物Jan Leike。之后在九月,CTO Mira Murati也宣布离职,有消息称她正在为她新的初创公司融资。
同时,联合创始人、前总裁Greg Brockman在休了三个月的长假之后回到了OpenAI。

OpenAI用了一年的时间来处理高层之间的人际冲突,如今终于暂时稳定了局面。坏消息是多数的创始成员都已经离开,好消息是这场宫斗终于结束。
Sam Altman有了稳定的权利,接下来或许可以更顺利地推进他想象中的AI发展方向,包括将OpenAI从非盈利组织变成赢利组织来更好融资,推出更多可以商业化的产品等。
2024年10月,Sam Altman为OpenAI完成了新一轮66亿美元的融资,公司估值来到1570亿美元。但OpenAI烧钱之狠也是有目共睹的:
《纽约时报》获得的融资文件显示,OpenAI2024年预计收入达到37亿美元,但预计亏损将达到50亿美元,而2026年亏损可能会高达140亿美元,这一估算还不包括给员工的股票激励兑现。

虽然OpenAI承诺投资人收入在成倍增长,预计在2029年达到1000亿美元,实现盈利,但按照这样的烧钱进度,OpenAI在2025年的两大趋势会是必然:*是大规模融资;第二是更激进的商业化。而这其实和2024年OpenAI的路线年,OpenAI没能如预期发布GPT5,这让市场中不少人失望,但惊喜的是4o的多模态进展。此外,o1和最近o3的发布让人看到模型能力进化的另外一种路线。
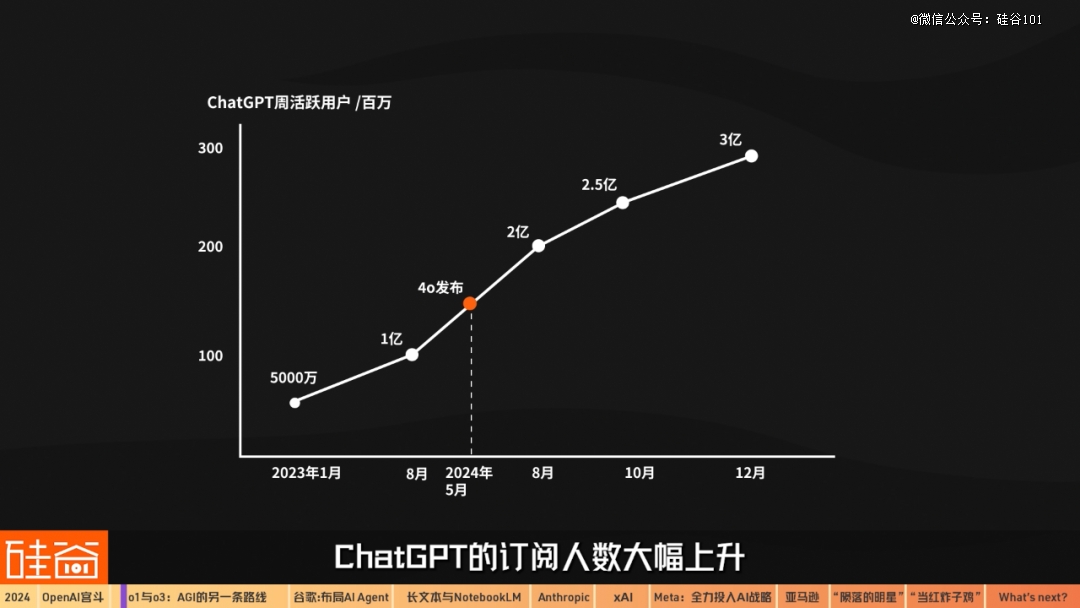
Chapter 1.2 o1与o3:AGI另一条路线月初,OpenAI发布多模态4o功能,正式与谷歌等竞争对手进入AI多模态之战,可以实时对音频、视觉和文本进行推理。事实证明,4o发布之后,特别是在免费版本中提供有限的4o功能和4o-mini之后,ChatGPT的订阅人数大幅上升,依然在2C领域上远超竞争对手。2024年12月,ChatGPT的周活跃用户已经超过3亿人。
o1这个内部代号为“Strawberry”的强大模型更新,让我们看到了在预训练上堆参数的“大力出奇迹”之外的、通过推理阶段的算法突破找到一条新的通往AGI的道路。
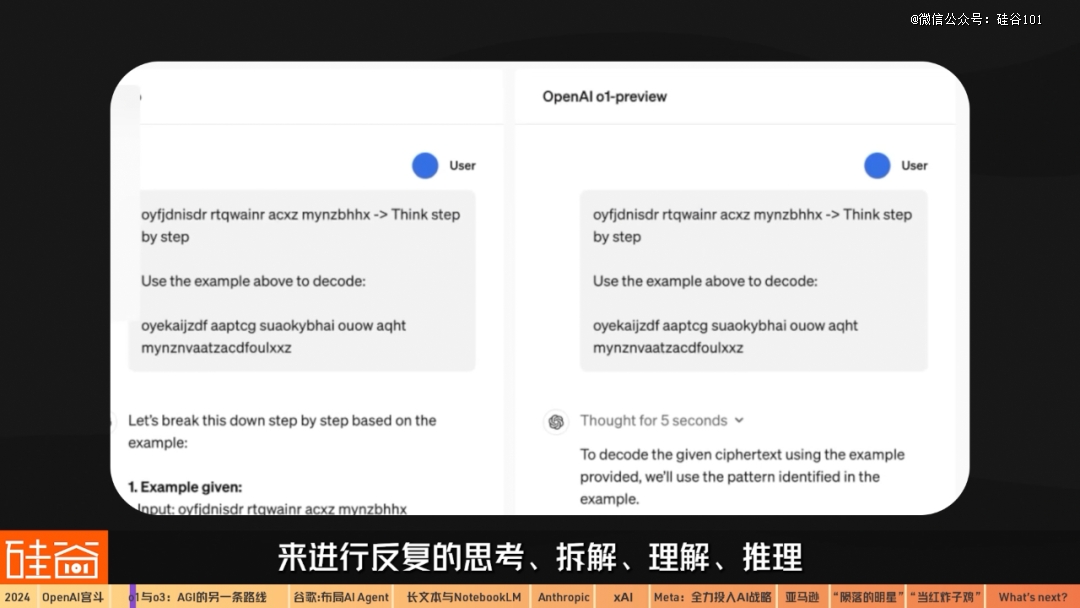

随着我们转向强化学习(RL)训练来加强AI的推理能力,我们最近发布了AI的五个等级,比如会话AI(聊天机器人)、推理AI、代理AI等。我们的确发现这能帮助AI在这个五层框架内,达到下一个水平,这也是为什么我们将模型系列重新命名为o1。
制作o1模型是因为大语言模型更多是即时生成的,如果想执行许多其他复杂的任务,你需要将其分解为多个任务,以便它们可以逐一完成,人们称之为代理或工作流。
我认为这种方法同时还很好地降低了成本:因为模型可以逐步执行很多步骤,这让模型训练变得更容易。所以,为了获得更好的推理质量,在延迟上做一部分牺牲。这很可能是一种趋势。
这12天的发布活动中,除了前几天的o1正式版、生成视频模型Sora在历经10个月之后终于开放给公众、以及集智能写作、代码写作和定制化AI agent为一体的AI工作台Canvas之外,
其它的更新比如说ChatGPT Search升级、与苹果Apple Intelligence的协作等等,看上去就非常不痛不痒,甚至感觉是在给12天的发布会凑数
直到最后一天,OpenAI给出了一个王炸:o3。o3是2024年9月发布的o1的下一版本,因为o2涉及其它公司的版权商标问题,所以OpenAI直接把这个更新跳了一个数字。
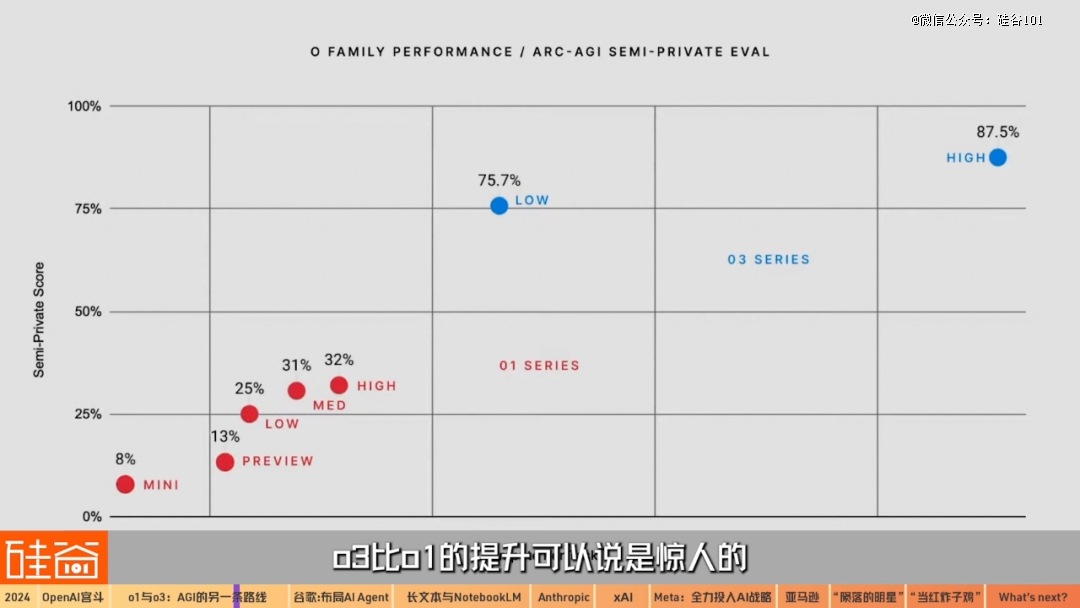
o3在数个测试上的能力,无论是程序员编码竞赛(Codeforces)中超过99%的人类程序员,还是博士水平的科学问题(GPQA)已经超过一般人类博士生,还是最难的前沿数学测试,还是抽象推理能力基准考试ARC-AGI,o3比o1的提升可以说是惊人的,而这个版本的更新仅仅用了三个月的时间。
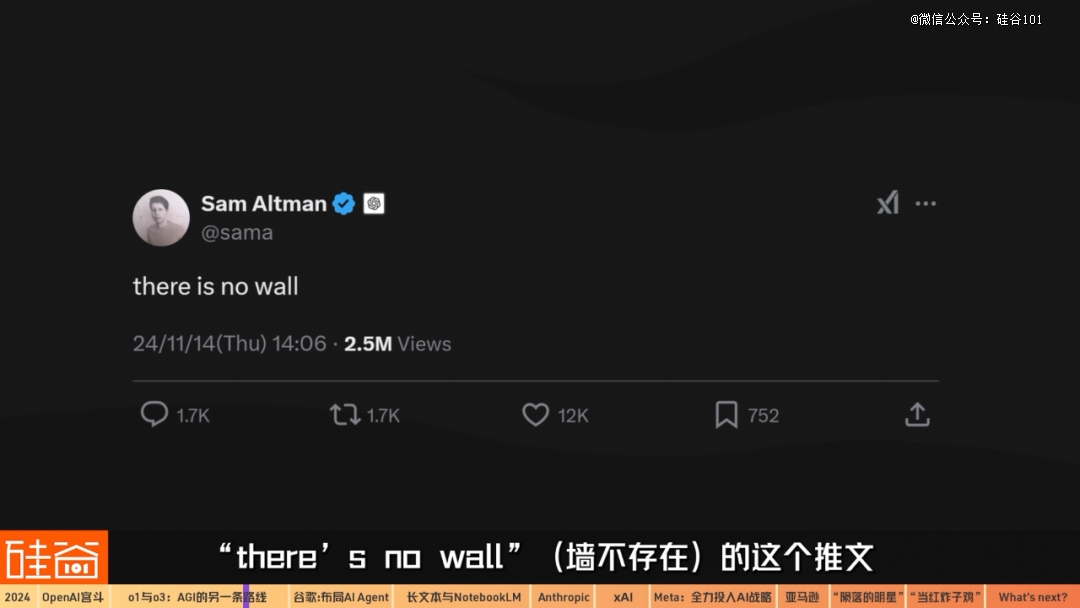
这让AI业界的不少人相信,OpenAI在o1和o3这个强化推理这个范式转变是有效的,这让担心AI大模型已经“撞墙”的人们稍微松了口气:至少AI模型的发展还在推进。大家也能理解之前Sam Altman说的“there’s no wall”(墙不存在)的推文了。
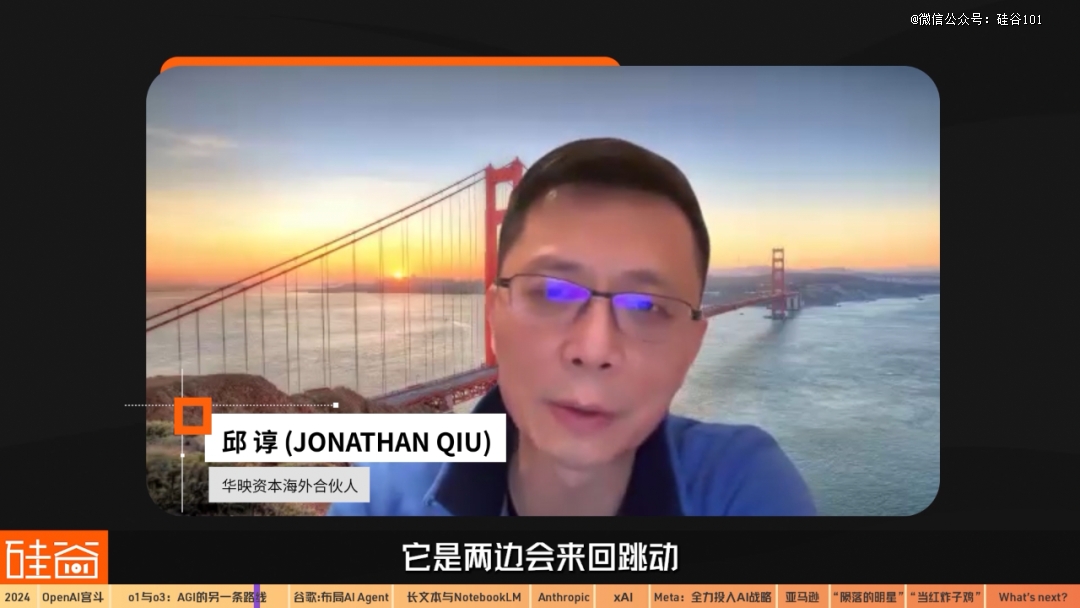
这样的“钟摆”科技途径发展,就像之前英特尔提出的Tick-Tock计划一样,会成为双重并行的发展主旋律。
Tick-Tock的意思是左边是数据驱动,右边是规则驱动,两边会来回跳动。一会是用更好的数据集去训练它,但同时用更好的算法去推动它,所以就是在算法跟数据两边Tick-Tock(摇摆)苹果手机在国内怎么使用whatsapp。因为现在o1和o3更多的还是算法,但是之前包括 GPT 其实也是数据集的驱动。所以,在(数据和规则)这两边的摇摆的时候,应该会摇出下一个大的 breakthrough(突破)或者milestone(里程碑)。
如果o3的路线能将我们带到“五层超级人工智能”的第二层,那什么突破能将我们带到再下一层自主autonomous AI呢?不知道OpenAI在2025年能否给我们这个答案。

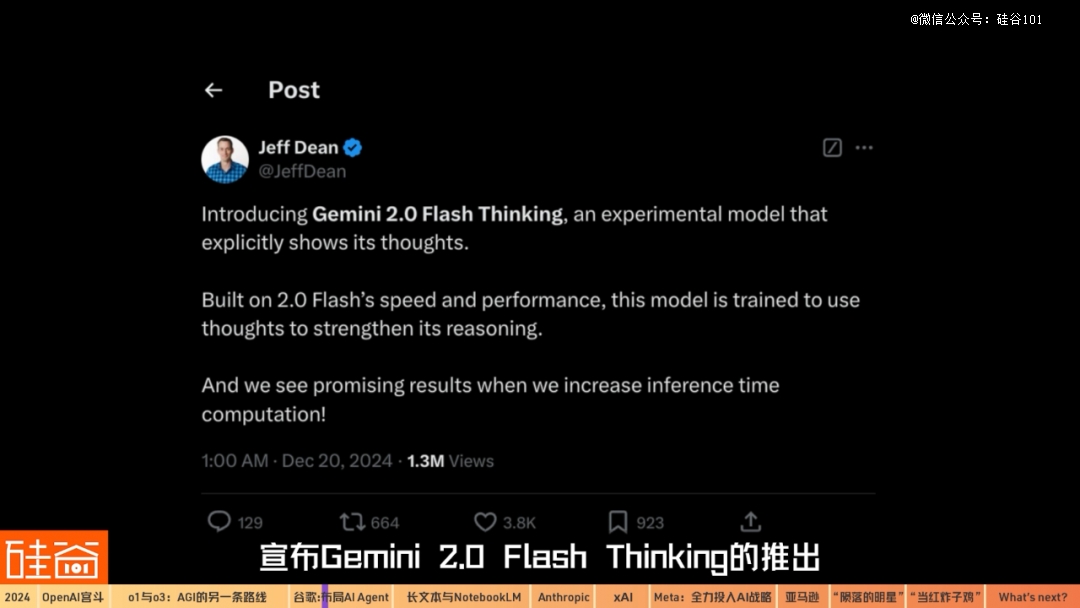
2024年12月底,OpenAI进行12日发布会期间,谷歌进行了几个重磅发布。如果OpenAI没有压轴的o3,年底的风头几乎全都会被谷歌抢走。谷歌首先在12月12日发布了多模态大模型Gemini的第二代Gemini 2.0,谷歌CEO Sundar Pichai在发布公告中表示,如果说Gemini 1.0是用于组织和理解信息,那么Gemini 2.0则是让信息变得更有用。
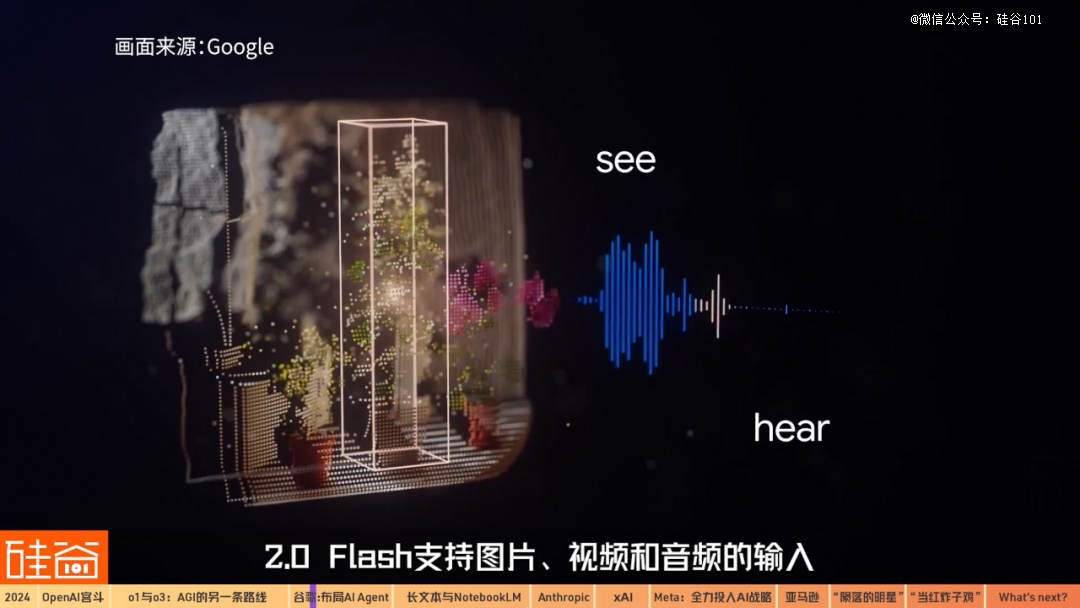
怎么理解Pichai说得第二代Gemini能让“信息变得更有用”呢?首先,Gemini2.0在多模态功能上更强大。谷歌目前对外开放的新模型是Gemini 2.0 Flash,在响应时间上比上一代的1.5 Flash性能更强、延迟性更低。在多模态上,2.0 Flash支持图片、视频和音频的输入以及多模态的输出。

在2024年5月的谷歌I/O大会上,非常惊艳到我的项目“多模态虚拟助手Project Astra”,也有相当的进展。
在Astra Gemini 2.0的demo中测试人员使用手机和AI来进行实时交互,包括快速提示公寓大楼的安全密码、随时对公共交通路线进行询问等,人们也可以带着智能眼镜进行更沉浸式的多模态交互。
所以失败了多年的Google Glass是不是终于能活过来了呢?也许在2025年我们会有新的答案。
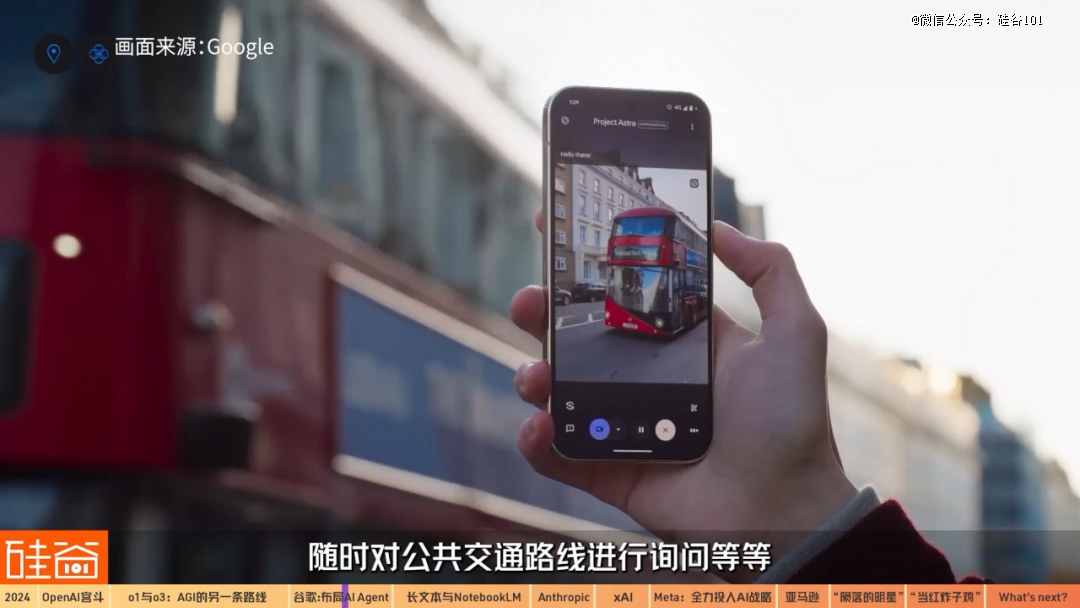
虽然目前来看,这个项目还在比较早期的阶段,如果我们看看之前提到的OpenAI定义的五个AI层级,Agent能自主行动完成任务已经是第三个层级了。
这也展现出谷歌对AI agent的押注,而这个赛道也被很多人认为将在2025年是个极其火热、面临爆发的赛道。
对于谷歌来说,全力押注AI agent也很自然:如果谷歌*钱的产品,也就是“搜索”将会被AI交互颠覆,那么AI agent的入口、屏幕、交互、模型反馈都是谷歌必须要占据的领地。

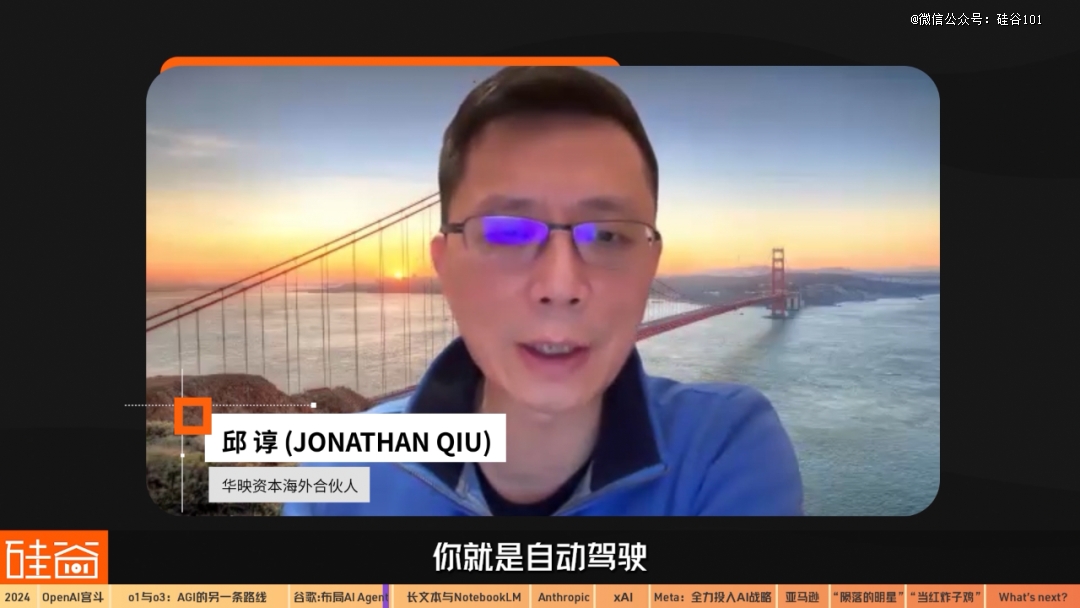
如果你是 AI application(应用),你就是Copilot(副驾驶);AI agent(智能体)是自动驾驶, Copilot 就是辅助驾驶。
在2024年,被谷歌卷起来且处于业界*地位的还有它的“长文本”的能力,这个长文本能力指的是让大模型理解超长的上下文。而基于这个能力,谷歌在2024年也衍生出了一些爆款AI产品,包括NotebookLM。2024年2月15日,谷歌的Gemini 1.5 Pro把长文本能力卷到100万tokens;

同时,谷歌新发布的论文,描述了一种新的注意力技术“inifini-attention”(无限注意力),能使Tranformer大模型在有限算力情况下处理无限长度的输入。

如果我们不算Gemini的模型,那么在业界现有的*的大型语言模型,允许的Token(AI处理文本的单元)数量大约在10万到20万之间。假设一个token相当于一个单词,则大致可以包含总共10万到20万个词作为给AI的提示词。

有谷歌的Gemini底座大模型的多模态和长文本能力支撑,NotebookLM的AI播客功能可以将文档、视频或者音频总结生成一男一女对话的方式,让用户用“听内容”的方式获取信息,在播客podcast这种媒体形式无比流行的硅谷形成了病毒式传播的现象级别产品。
虽然回答的内容比较浅显,交互也比较像相声中的捧哏,但NotebookLM在对内容的抓点和总结能力是非常精准的,生成的两位AI主播的对话也非常自然流畅,AI感很低,我也大概能感受到这个产品之后的潜力还是会非常大。
12月中旬,谷歌发布NotebookLM Plus,新加入audio overview功能、允许用户在播客中间打断AI主播,提出建议或问题进行交互,同时用户还可以自定义播客风格和主题。

外界猜测他们会自己重新做一个NotebookLM的产品用于更好的商业化,但很有趣的是,有的VC投资人并不看好这个项目。

你可以理解他是个产品创新。NotebookLM是Google Labs出来的,但Google自己是有底座模型的。Notebook LM用的底座其实也不是Google Gemini,而是谷歌自己内部的一个定制化底座。所以,如果你不是那么懂底座,纯第三方的来用谷歌Gemini API,你未必能做得出来NotebookLM。
究其根本,OpenAI的商业模式是一个大模型提供方,所以一定要保证模型的*性,但谷歌是完全不同的商业模式,它的首要任务是保证技术不落后且当谷歌搜索被AI颠覆时,自己是准备好的。
所以在多模态的AI第二轮大战中,OpenAI是进攻者,而谷歌依然是防御者,下一场硬仗无论是第二层的reasoning,还是第三层的autonomous AI agent,2025年都会非常精彩。

2024年在融资上,Anthropic从亚马逊获得了新一轮40亿美元的融资,使得公司估值达到400亿美元。
从外界反馈来看,Anthropic的模型在技术上是非常强的,特别是Claude在编码任务中表现出色,尤其是在复杂代码生成和解决方案自动化方面,非常受到工程师们的推崇。

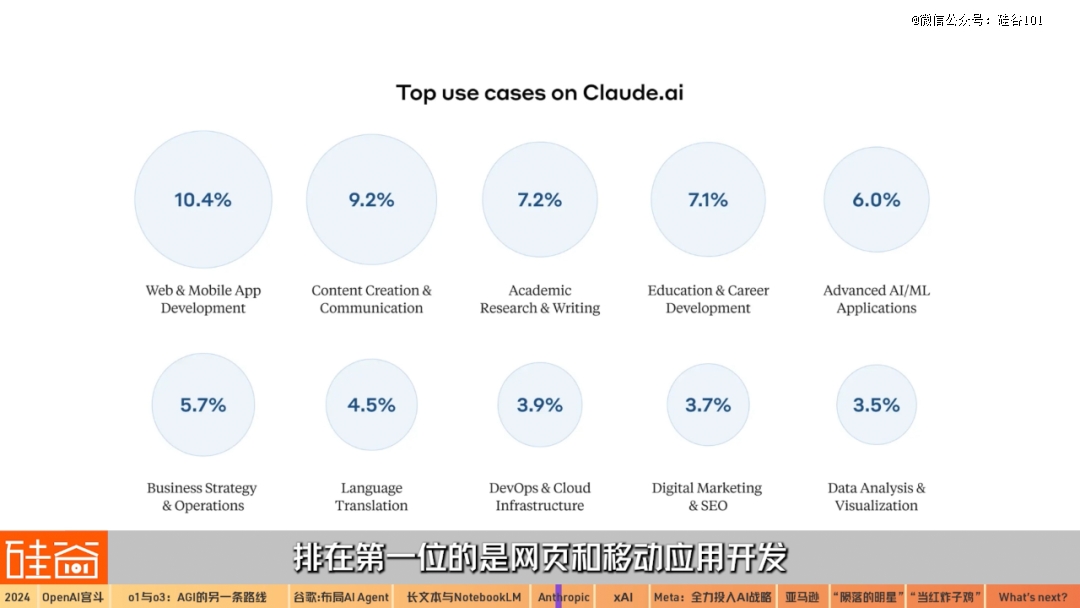
12月底,Anthropic从用户与Claude的对线万条,进行分析和总结后发现,用户在Claude.ai上的主要使用场景排在*位的,是网页和移动应用开发,占比为10.4%。
很多开发人员认为,Claude 3.5 Sonnet会非常适合需要深度理解和复杂推理的应用程序,而OpenAI的模型对于较简单的任务可能更具成本效益。
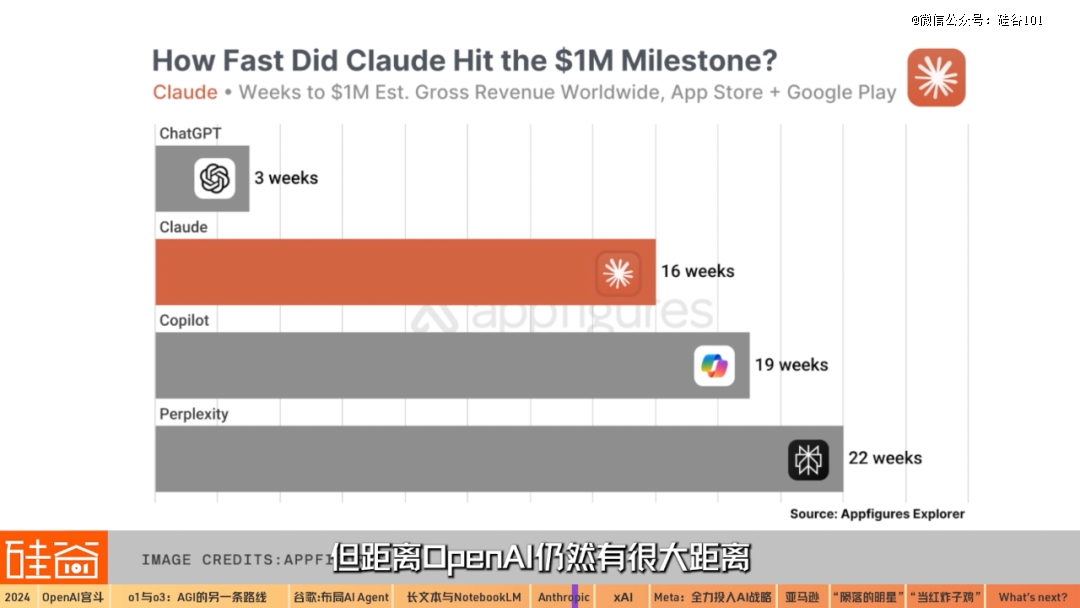
而Claude AI的2C聊天机器人,在iOS和安卓移动应用程序上收入100万美元的里程碑,用了整整16周,而这个门槛OpenAI的ChatGPT用了三周就达到了。虽然快于微软的Copilot和Perplexity,但距离OpenAI仍然有很大距离。
之前媒体的报道说,Anthropic在2024年的收入会超过10亿美元,比之前预测的要高很多,说明市场还是非常买账Anthropic的模型能力,特别是最近他们又挖了很多OpenAI的核心人员过去。
看上去,这个OpenAI的*竞争对手在2025年会继续在2B和2D领域上发力,而对2C消费者端来看,暂时不会对OpenAI和谷歌带来太大的威胁。
如果还有其它顺便的事,就是马斯克数次把OpenAI告上了法庭。12月24日,马斯克旗下的xAI宣布完成60亿美元的C轮融资。英伟达,AMD,a16z,红衫等公司和机构参与,也表明业界对xAI的潜力的看好。
要知道在半年之前的2024年5月,xAI刚完成60亿美元的B轮融资,足以说明马斯克的融资能力。
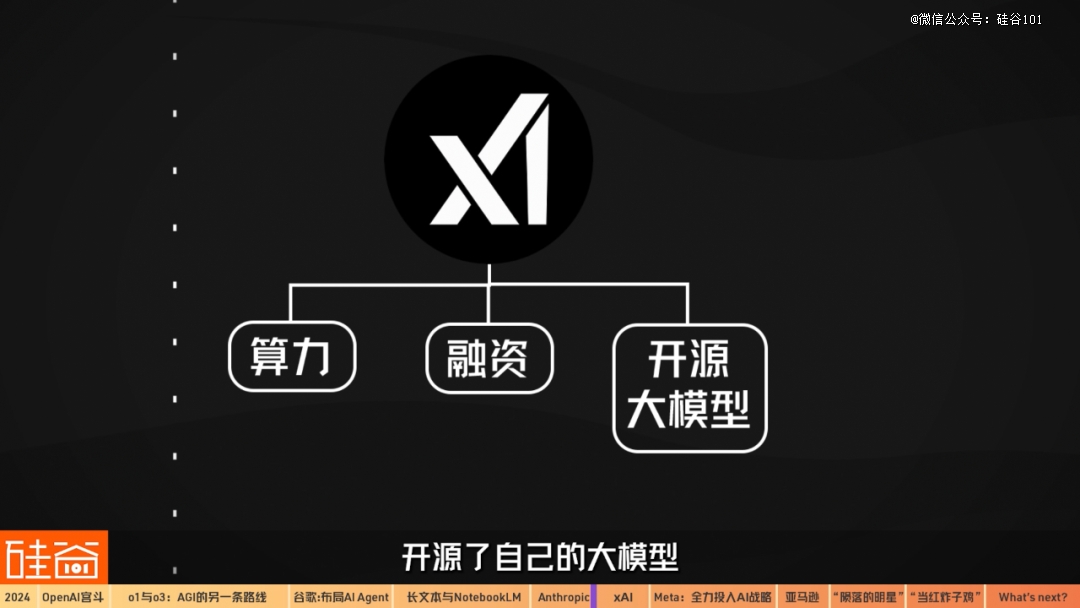
除了钱之外,马斯克还是*个搞定大规模算力集群的:2024年,xAI位于美国田纳西州孟菲斯市的数据中心正式投入使用,历时122天建成创下纪录。
这个名为“巨人”(Colossus)的数据中心里面部署了英伟达的10万块GPU芯片,成为全球开发和运行人工智能技术的规模*、算力最强的芯片集群之一。而马斯克说以后还有计划继续拓展到20万块GPU的规模。

在大模型上发布上,Grok的速度其实是要比竞争对手慢一些的。在8月中旬,xAI发布了Grok-2和Grok-2mini两款AI模型的测试版,比此前发布的Grok-1.5有了非常大的进步。
10月,xAI发布了*应用程序编程接口(API)。目前,xAI API只有一个模型,称为“Grok-beta”。
其实xAI虽然入局晚了些,但优势还是非常多的:除了上面我们说到的算力和融资之外,xAI还有社交网络X和特斯拉的*数据,以及机器人Optimus等项目的结合潜力。

相当一段时间以来,Grok的聊天机器人只向马斯克旗下的“X”用户提供,但在2025年很可能马斯克会全面开放Grok。
除了iOS程序在测试之外,网页版已经准备就绪,写着coming soon(准备就绪),感觉2025年xAI会正式加入战局。
在大模型方面,脸书在2024年持续更新Llama开源模型。12月6日,Meta发布新款Llama开源模型:70亿参数的Llama 3.3、又称Llama 3.3 70B。扎克伯格说,下一步就是明年Llama 4的亮相。
除了在大语言模型上的进展外,Meta也一直在探索除了“大语言模型”(LLM)之外的其它AI路径:2024年12月11日,Meta新发布了Large Concept Model(LCM),翻译过来是“大型概念模型”。

另外,由于Meta 2024年在智能眼镜上的尝试成功,以及旗下Facebook、 WhatsApp、 Instagram、Messenger、Threads等庞大的用户群体,还有AI和广告结合的前景,市场非常看好Meta如今在AI大战中的位置。
Jefferies的分析师甚至将Meta选为步入2025年生成式人工智能的“赢家”。不少二级市场的报告认为,Meta下一代与AI结合的Orion AR眼镜将成为新一代硬件入口,Meta在2024年推出的Ray-Ban Meta很初步的将AI功能引入其中,受到市场好评。
可能在2025年,下一代智能眼镜上Meta就会引入屏幕显示,届时就会释放出更强大的AI交互功能。

说到智能硬件,苹果在2024年发布了Apple Intelligence三件套,但因为端侧模型和agent的发展可能还没有到能让硬件产业与AI结合得特别好的程度,苹果在AI进展并不大。
很多人认为苹果最终还是要自己开发底座大模型,不能完全靠接入OpenAI的ChatGPT,而等硬件与AI结合的那一天,就是手机与智能眼镜的市场大战了,目前押注得*的Meta和苹果将终有一战。
说回Meta的其它AI产品布局:在AI Chatbot方面,Meta旗下的几款王牌社交媒体都已经不同程度的引入了AI对线月表示,Meta的AI数字助理“每个月有将近6亿的活跃用户”。

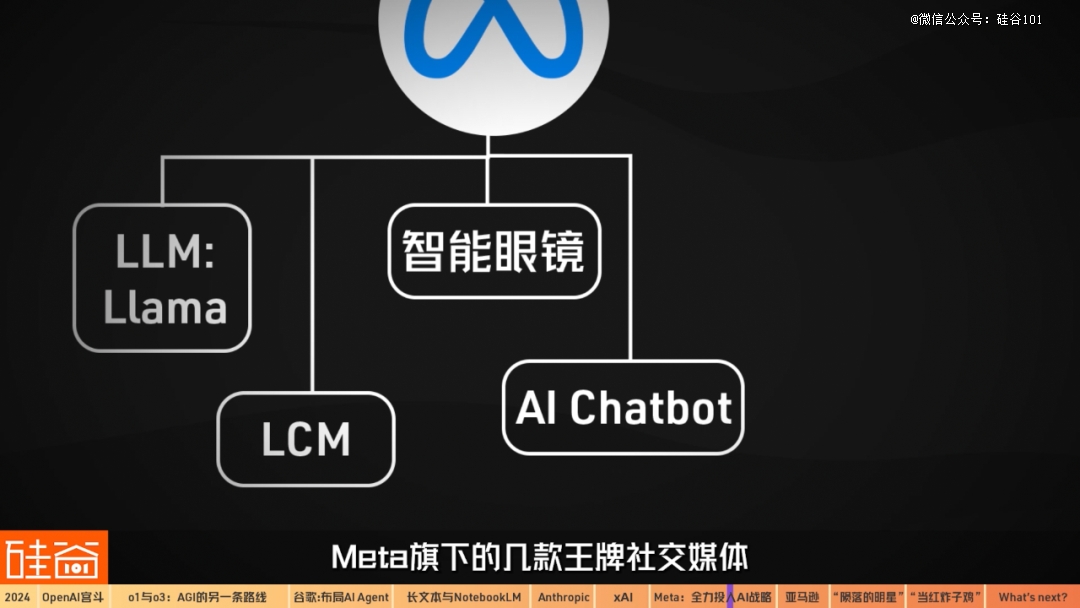
Meta在12月表示,目前超过100万的广告商在使用Meta的GenAI工具,他们在一个月之内制作了超过1500万条广告。
同时,也有分析认为,Meta可能会在自家的开源模型Llama上进一步开发出企业级客户服务的业务,也将会是一块很大的蛋糕。
在2024年,小扎非常积极的出现在各个媒体采访中,一遍又一遍阐述着Meta的未来,不再是单纯的Metaverse,而是新一代的AI交互,一个融合了AI,混合现实和元宇宙的未来。
2024年9月,开始在形象和穿搭上大转型的扎克伯格穿了一件T-shirt,上面写着“Aut Zuck Aut Nihil”,这个细节被媒体捕捉到。

这个短语是拉丁短语“Aut Caesar Aut Nihil”的变形,意思是“要么是凯撒,要么什么都不是”;

最后几家科技巨头中,再说说亚马逊。亚马逊的路线和其它几家都不太一样,采取的是一个卖铲子生意的模式。
他不拼模型、拼算力、拼芯片,虽然各方面都有自研的产品,但把他们整合在一起,再加上市面上所有的好东西,打个包卖给客户们,帮甲方降本增效,做好2B的生意,也是非常聪明的做法了。
第二,不光提供满足万亿参数大模型训练和推理需求的自研芯片产品,包括与Anthropic绑定合作的十万张亚马逊Trainium自研芯片AI计算集群,还有为中小企业和初创公司提供能降本增效的服务与技术;

对于很多需要用到AI的初创公司,要算力并不一定需要自己买卡,要用模型并不一定要自己训练。就像需要萝卜青菜也并不需要自己去务农种菜,可以去超市直接买,就看最终的成本账能否算得过来了。
这也显示出,亚马逊押注2025年市场对算力的需求只增不减。而随着需求逐渐从训练转移到inferencing推理,算力市场的更多创新服务以及基建会进一步完备。


*家是Character.ai,成立于2021年,利用大模型生成各种人物和角色风格的对线月,Character.AI在苹果App Store和Google Play Store发布了移动应用程序,*周下载量就超过170万次,并被Google Play评为2023年度*AI应用。然而,2024年年初,公司被频频爆出融资困难,商业化不顺利,开始寻求收购。
另外一家公司是Inflection.ai,这家公司做大模型,上面叠加“个人AI伴侣”用途的聊天机器人Pi,主打情感陪伴市场。
做大模型吧,太烧钱;不做大模型吧,没有技术壁垒和护城河。这么一看,AI时代的创业真的太难了。

所以你怎么去把控这个节奏?我觉得Perplexity这家公司其实还是把控得很不错的:他到今天也没有完全重新训练自己的底座。我觉得他会有那么一天的,但是他要把握这个节奏,别步子迈得过大,还没到那一天的时候,就已经把钱给烧完了。这个是比较危险的,也是 AI 创业比互联网可能更难一点的地方。

再总结一下2025年被认为是冉冉上升的明星AI项目。首先是前面Jonathan提到的Perplexity:2024年年底,公司完成了新一轮5亿美元的融资,估值达到90亿美元。
这家公司成立于2022年,可以说重新定义了全球*个对话式AI搜索引擎,月活跃用户已经达到1500万人次,日活跃用户200万人,连英伟达创始人黄仁勋也为它站台,称每天都会使用。Perplexity的聪明之处在于,自己不训练模型,而是使用多种大型语言模型,包括GPT、Claude、LLAMA、Mixtral等,以及来自多个搜索引擎的排名信号和第三方数据提供商的数据。

2024年,硅谷还有另外一家公司非常受人瞩目:Physical Intelligence。
我最开始听到这家公司是从OpenAI联合创始人以及特斯拉FSD前负责人Andrej Karpathy的口中。
他曾在一个小型的聚会上分享说,有很多项目找他投资,他答应的原因只是为了帮助朋友,毕竟他的名字在天使投资人的那一栏能帮很多项目更容易拿到投资。但为数不多的他真心想投资且看好的项目,就当属Physical Intelligence了。这家公司通过AI模型为机器人打造“大脑”,在2024年11月完成新一轮4亿美元的融资,估值来到20亿美元,投资者包括亚马逊创始人贝佐斯还有OpenAI。
同时,在11月初,Physical Intelligence发布了*通用基础模型π0,也被是认为具身智能发展上的重要一步。

Physical Intelligence表示,π0将使得机器人变得更容易编程和使用,使其能够更高效地执行多样任务。

2024 年*的进展,我会投给o1和π0。我觉得π0更多是 training data driven(数据驱动)的路线更代表的是algorithm(算法)驱动的路线肯定也要在算法上继续做迭代,也可能在推理侧引入一些方法。当然难一点就是推理,因为具身智能的推理侧要在端侧发生,可能对算力的要求会更高一些。

同时,斯坦福的机器人中心在2024年开业了,我也去参加了开业仪式,有机会我们去那里采访一下跟大家分享最新的项目和有意思的进展。
由于篇幅原因,还有很多科技巨头的进展、初创企业和新趋势我们没办法一一列举,包括AI视频生成的初创公司Pika和Luma,音乐生成初创公司Suno,最近很火的AI编程应用Cursor和Devin,李飞飞博士的World Labs、该有2025年初引起一片震撼的DeepSeek等,之后有机会我们详细做成单独选题来聊。
总的来说,2024年的硅谷非常精彩,有混乱,有质疑,有倒闭收购,也有为了AGI信仰继续战斗的科技从业者们。

我认为,虽然现阶段的GPT-4可以做的事越来越多了,但是更大、更强的模型在某种意义上会让模型的使用变得更容易。所以,如果有了GPT-5或者Claude 4、5,那么基于GPT-4的一些自我工程可能就不再必要了。
然后基于大模型,人们会构建各种不同的垂直模型。刚开始垂直模型也比较大,但随着包括蒸馏模型、量化模型等技术,模型会变得更小但是更有效率、更有性价比,而且模型质量不会下降太多。
我认为这两条主线将会持续很长一段时间,希望有第三种并行努力的方向,那就是寻找不同的模型架构,因为现在的模型基本都是基于Transformer的,还有一些基于diffusion模型用于生成图像等中间工作。我希望能有其他非transformer、非diffusion的模型架构出现,让生成结果更有效、更高质量、同时降低成本。如果在这方面能有所突破,将再次对AI行业产生巨大的影响。
在硅谷的AI生态中,已经衍生出了多个派系:有更大的模型、大模型衍生出的垂直模型、不信仰Transformer而在探索其它通往AGI路径的研究者,同时也有应用、硬件、agent智能体、机器人、无人驾驶,还有“卖铲子”的英伟达、数据中心、电力上下游等等,这些生态在2024年得到了进一步的巩固与布局,而在2025年,我们会看到更多技术的进展。当然,硅谷只是AI发展的其中一个主力战场,全球其它市场的AI也有非常快速的发展,今天我们只是稍微总结了一些硅谷的情况,也欢迎大家给我们留言最值得提的公司,技术或者事件,这对我们团队更进一步探索AI产业非常有帮助。