代理ip地址的软件下载


作为一个 Python 新手,你必须熟悉基础知识。在本文中我们将讨论一些 Python 面试的基础问题和高级问题以及答案,以帮助你完成面试。包括 Python 开发问题、编程问题、数据结构问题、和 Python 脚本问题。让我们来深入研究这些问题
深拷贝是将对象本身复制给另一个对象。这意味着如果对对象的副本进行更改时不会影响原对象。在 Python 中,我们使用 deepcopy()函数进行深拷贝,使用方法如下:
浅拷贝是将对象的引用复制给另一个对象。因此,如果我们在副本中进行更改,则会影响原对象。使用 copy()函数进行浅拷贝,使用方法如下:
Q.4 到 Q.20 是新手经常会被问到的一些 Python 基础题,有经验的人也可以参考这些问题来复习这些概念。
线程是轻量级的进程,多线程允许一次执行多个线程。众所周知,Python 是一种多线程语言,它有一个多线程包。
GIL(全局解释器锁)确保一次执行单个线程。一个线程保存 GIL 并在将其传递给下一个线程之前执行一些操作,这就产生了并行执行的错觉。但实际上,只是线程轮流在 CPU 上。当然,所有传递都会增加执行的开销。
一个类继承自另一个类,也可以说是一个孩子类/派生类/子类,继承自父类/基类/超类,同时获取所有的类成员(属性和方法)。
继承使我们可以重用代码,并且还可以更方便地创建和维护代码。Python 支持以下类型的继承:
Flask 的会话会话使用签名 cookie 来允许用户查看和修改会话内容。它会记录从一个请求到另一个请求的信息代理ip地址的软件下载。但如果要修改会话,则必须有密钥 Flask.secret_key。
Python 用一个私有堆内存空间来放置所有对象和数据结构,我们无法访问它。由解释器来管理它。不过使用一些核心 API,我们可以访问一些 Python 内存管理工具控制内存分配。
答案是否定的。那些具有对象循环引用或者全局命名空间引用的变量,在 Python 退出是往往不会被释放
如果我们不知道将多少个参数传递给函数,比如当我们想传递一个列表或一个元组值时,就可以使用*args。
验证 Python 是否区分大小写的方法是测试 myname 和 Myname 在程序中是不是算同一个标识符。观察以下代码的返回结果:
如图这个字符串既包含前置空格也包含后置空格. 调用 lstrip() 函数去除了前置空格。如果想去除后置空格,使用 rstrip() 函数。
我们在写代码时,有时可能只写了函数声明而没想好函数怎么写,但为了保证语法检查的正确必须输入一些东西。在这种情况下,我们使用 pass 语句。
如果在一个内部函数里。对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就是一个闭包。
在 Python 中我们有 7 中运算符:算术运算符、关系 (比较) 运算符、赋值运算符、逻辑运算符、位运算符、成员运算符、身份运算符。
因为在 Python 中以下划线开头的变量为私有变量,如果你不想让变量私有,就不要使用下划线. 如何声明多个变量并赋值?
以上是 Python 高级面试问题和答案,新手也可以参考这些问题以获得进阶的 Python 知识。
本篇文章介绍了一些重要的 Python 面试问题和答案,后续我们还会增加。在你面试之前应该熟练掌握这些。如有想添加的问题欢迎随时评论。
1)迭代器是一个更抽象的概念,任何对象,如果它的类有next方法和iter方法返回自己本身。对于string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调用iter()函数,iter()是python的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个StopIteration异常
2)生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数据的时候使用yield语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了__iter__()和next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出StopIteration异常
Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
在调用外部代码(如C/C++扩展函数)的时候,GIL 将会被锁定,直到这个函数结束为止(由于在这期间没有Python 的字节码被运行,所以不会做线、find和grep
grep命令是一种强大的文本搜索工具,grep搜索内容串可以是正则表达式,允许对文本文件进行模式查找。如果找到匹配模式,grep打印包含模式的所有行。
一、垃圾回收:python不像C++,Java等语言一样,他们可以不用事先声明变量类型而直接对变量进行赋值。对Python语言来讲,对象的类型和内存都是在运行时确定的。这也是为什么我们称Python语言为动态类型的原因(这里我们把动态类型可以简单的归结为对变量内存地址的分配是在运行时自动判断变量类型并对变量进行赋值)。
二、引用计数:Python采用了类似Windows内核对象一样的方式来对内存进行管理。每一个对象,都维护这一个对指向该对对象的引用的计数。当变量被绑定在一个对象上的时候,该变量的引用计数就是1,(还有另外一些情况也会导致变量引用计数的增加),系统会自动维护这些标签,并定时扫描,当某标签的引用计数变为0的时候,该对就会被回收。
经由内存池登记的内存到最后还是会回收到内存池,并不会调用 C 的 free 释放掉.以便下次使用.对于简单的Python对象,例如数值、字符串,元组(tuple不允许被更改)采用的是复制的方式(深拷贝?),也就是说当将另一个变量B赋值给变量A时,虽然A和B的内存空间仍然相同,但当A的值发生变化时,会重新给A分配空间,A和B的地址变得不再相同
1.django 中当一个用户登录 A 应用服务器(进入登录状态),然后下次请求被 nginx 代理到 B 应用服务器会出现什么影响?
Tornado 的核心是 ioloop 和 iostream 这两个模块,前者提供了一个高效的 I/O 事件循环,后者则封装了 一个无阻塞的 socket 。通过向 ioloop 中添加网络 I/O 事件,利用无阻塞的 socket ,再搭配相应的回调 函数,便可达到梦寐以求的高效异步执行。
POST的安全性比GET的高。这里的安全是指真正的安全,而不同于上面GET提到的安全方法中的安全,上面提到的安全仅仅是不修改服务器的数据。比如,在进行登录操作,通过GET请求,用户名和密码都会暴露再URL上,因为登录页面有可能被浏览器缓存以及其他人查看浏览器的历史记录的原因,此时的用户名和密码就很容易被他人拿到了。除此之外,GET请求提交的数据还可能会造成Cross-site request frogery攻击。
1) scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。而scrapy-redis一套基于redis数据库、运行在scrapy框架之上的组件,可以让scrapy支持分布式策略,Slaver端共享Master端redis数据库里的item队列、请求队列和请求指纹集合。
从start_urls里获取第一批url并发送请求,请求由引擎交给调度器入请求队列,获取完毕后,调度器将请求队列里的请求交给下载器去获取请求对应的响应资源,并将响应交给自己编写的解析方法做提取处理:1. 如果提取出需要的数据,则交给管道文件处理;2. 如果提取出url,则继续执行之前的步骤(发送url请求,并由引擎将请求交给调度器入队列),直到请求队列里没有请求,程序结束。
IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线. 优化索引、SQL 语句、分析慢查询;
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
大多数网站都是前一种情况,对于这种情况,使用IP代理就可以解决。可以专门写一个爬虫,爬取网上公开的代理ip,检测后全部保存起来。这样的代理ip爬虫经常会用到,最好自己准备一个。有了大量代理ip后可以每请求几次更换一个ip,这在requests或者urllib2中很容易做到,这样就能很容易的绕过第一种反爬虫。
上述的几种情况大多都是出现在静态页面,还有一部分网站,我们需要爬取的数据是通过ajax请求得到,或者通过JavaScript生成的。首先用Fiddler对网络请求进行分析。如果能够找到ajax请求,也能分析出具体的参数和响应的具体含义,我们就能采用上面的方法,直接利用requests或者urllib2模拟ajax请求,对响应的json进行分析得到需要的数据。
能够直接模拟ajax请求获取数据固然是极好的,但是有些网站把ajax请求的所有参数全部加密了。我们根本没办法构造自己所需要的数据的请求。这种情况下就用selenium+phantomJS,调用浏览器内核,并利用phantomJS执行js来模拟人为操作以及触发页面中的js脚本。从填写表单到点击按钮再到滚动页面,全部都可以模拟,不考虑具体的请求和响应过程,只是完完整整的把人浏览页面获取数据的过程模拟一遍。
用这套框架几乎能绕过大多数的反爬虫,因为它不是在伪装成浏览器来获取数据(上述的通过添加Headers一定程度上就是为了伪装成浏览器),它本身就是浏览器,phantomJS就是一个没有界面的浏览器,只是操控这个浏览器的不是人。利selenium+phantomJS能干很多事情,例如识别点触式(12306)或者滑动式的验证码,对页面表单进行暴力破解等。
5、谈下python的GILGIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大6、python实现列表去重的方法
init有一个参数self,就是这个new返回的实例,init在new的基础上可以完成一些其它初始化的动作,init
4、如果new创建的是当前类的实例,会自动调用init函数,通过return语句里面调用的new函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的init函数,也不会调用其他类的init
(当然还有其他自定义功能,有兴趣可以研究with方法源码)13、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
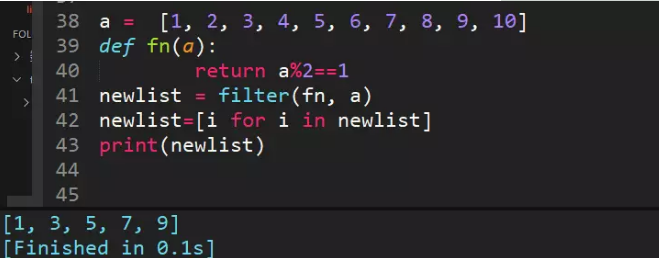
27、filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表
35、请列出你会的任意一种统计图(条形图、折线图等)绘制的开源库,第三方也行36、写一段自定义异常代码37、正则表达式匹配中,(.
题目本身只有a=%.03f%1.3335,让计算a的结果,为了扩充保留小数的思路,提供round方法(数值,保留位数)
